Version 1.3 Update (In-dev)¶
These notes describe changes being made in the upcoming Trellis v1.3 update expected for release at the end of March, 2022.
Using a node label taxonomy¶
Neo4j is a graph database that supports adding multiple labels and properties to each node in the database. My initial approach to labelling is that “more is better” because the more labels that are applied to a node, the richer the data, and the more sophisticated we can be in making decisions regarding that node.
I identified several issues with this approach:
Adding more than (4) node labels apparently decreases database performance because more space has to allocated for storage. Read more from David Allen on graph modeling labels: https://medium.com/neo4j/graph-modeling-labels-71775ff7d121.
Creating, identifying, or comprehending a database schema when each node can have 4+ labels is almost impossible. For reference, see the schema visualization I generated from a simpler & earlier version of the Trellis database, using the Neo4j
db.schemacommand:
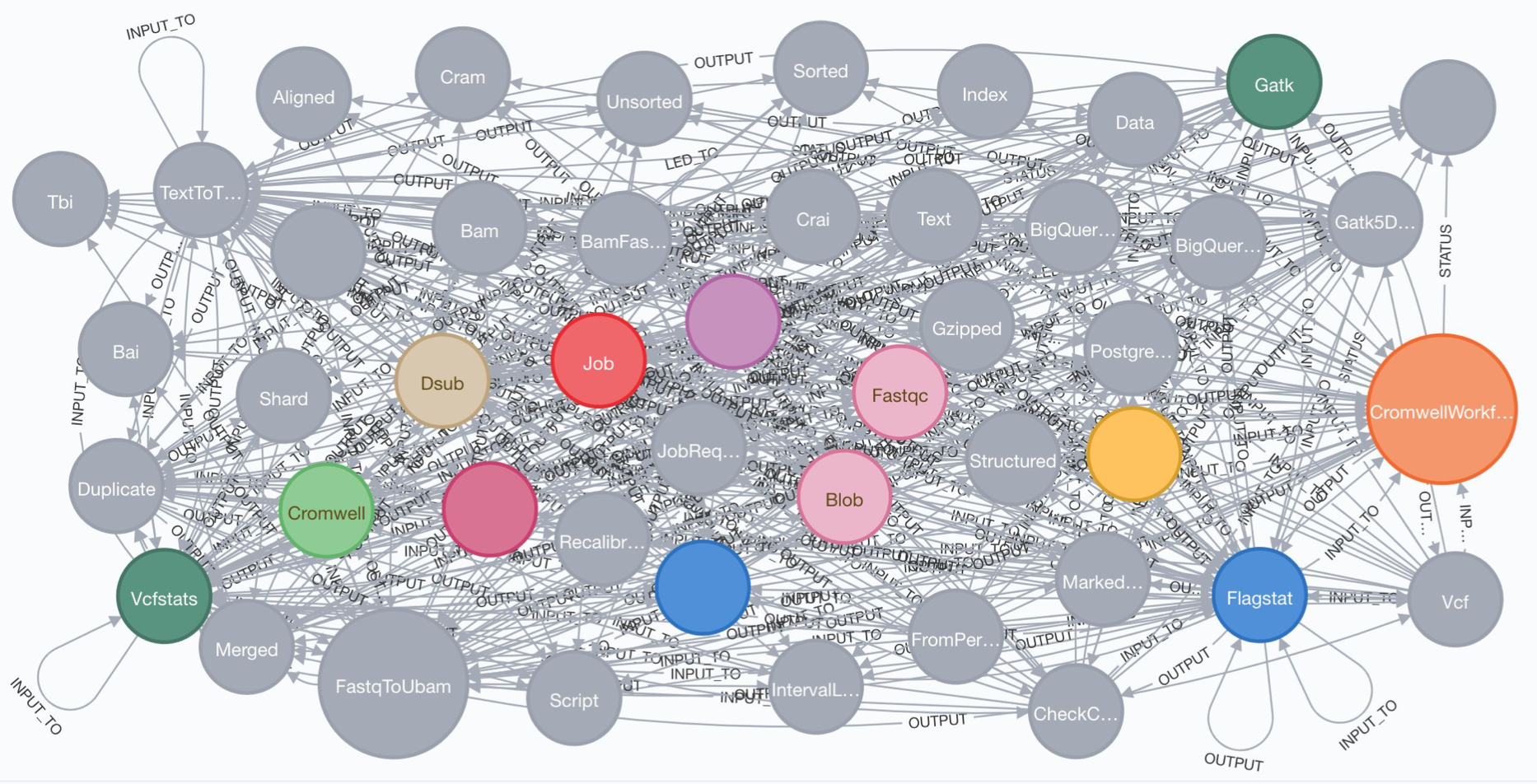
There seems to be a consensus between graph database professionals and groups publishing bioinformatics graph models that a single-model approach is the way to go. I see plenty of recommendations for single labels and I rarely see published examples using multiple labels.
So, I wanted to switch to a single-label model to simplify our schema without losing the richness of information offered by using multiple labels. For instance, I want users to know that nodes labeled “Bai” represent a specific type of index that is a data object stored in cloud storage. Using multiple labels, I would label this node :Bai:Index:Blob.
To do this using only a single label I opted to define a hierarchical taxonomy where each label inherits the properties of its parent.
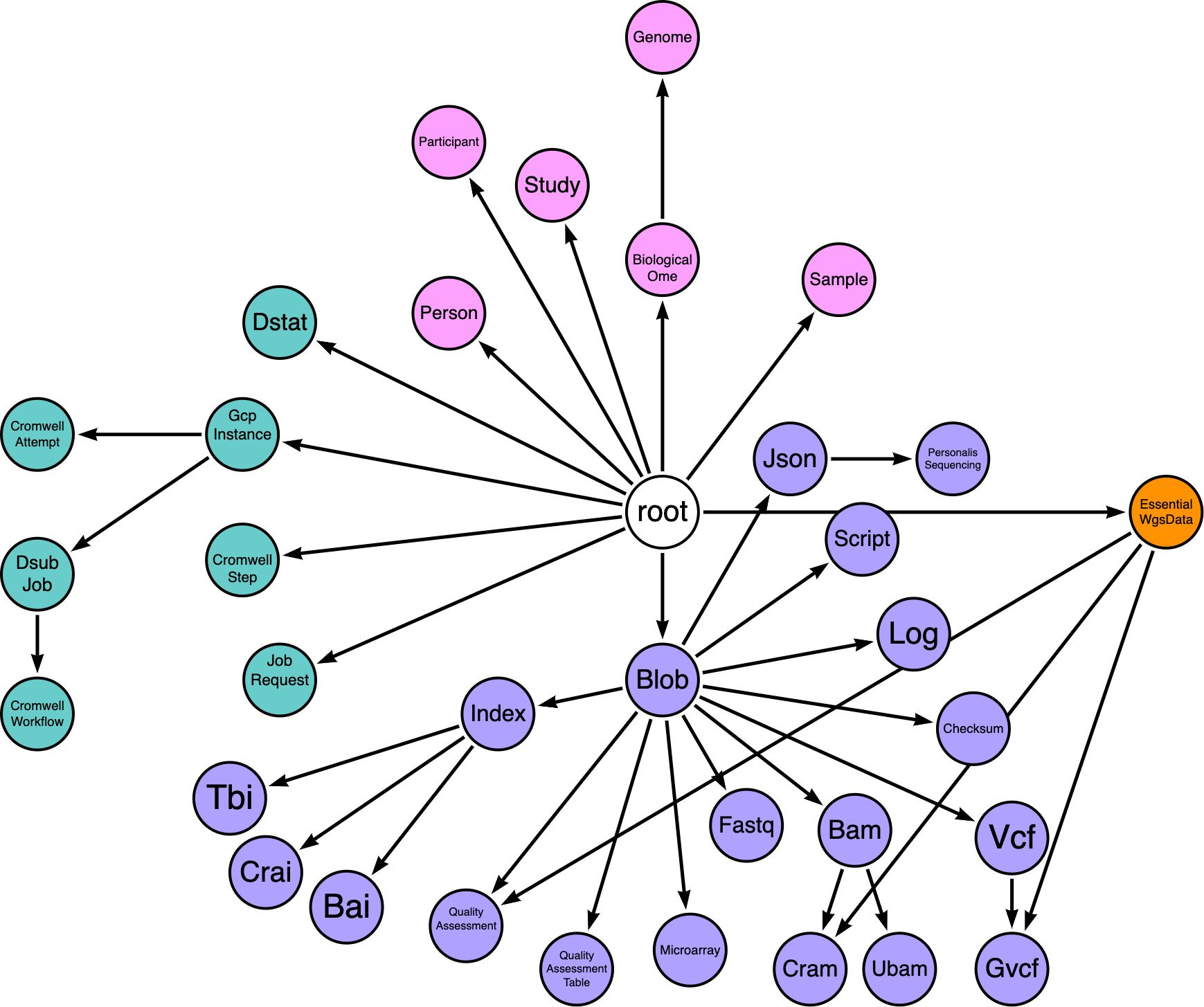
In this arrows diagram, purple represents the domain of data objects, teal the domain of tasks, and pink the domain of biomedical studies.
Another potential benefit of using a taxonomy is that Neo4j has a neosemantics for performing semantic inference on hierarchically structured categories. So in the future, if I want to apply an operation to all sequencing reads data, I could create a :SequencingReads label and then make :Fastq, :Bam, and :Cram all children of that label. That way, even if none of the nodes are labelled :SequencingReads, the database can infer that relationship and get all the children. I think. I still haven’t tried it but I’m look forward to finding a use case for it.
Assigning labels using a taxonomy¶
When a object is finalized, the create-blob-node function will use regex patterns to determine which labels apply to the object and then use a taxonomy to determine which of those labels will be applied to the node. If the system is working correctly, all the labels that match a given object should be on the same lineage or branch of the taxonomy. The label that is applied should be the most specific one that is farthest from the root of the taxonomy.
Using standard message classes¶
The application logic of Trellis is distributed among multiple serverless functions that operate independently. These functions coordinate operations by sending messages to each other via the Cloud Pub/Sub message broker availabe on Google Cloud Platform.
A potential point-of-failure in the current Trellis release is that each function formats messages according to its own logic. I essentially copy-pasted the same “format_pubsub_message()” method across all of the functions, but there is the potential for differences in formatting/structure to arise because every function has a separate instance of the method code. To address this, I created a trellisdata Python package that implements standard classes for reading and writing different kinds of Trellis messages.
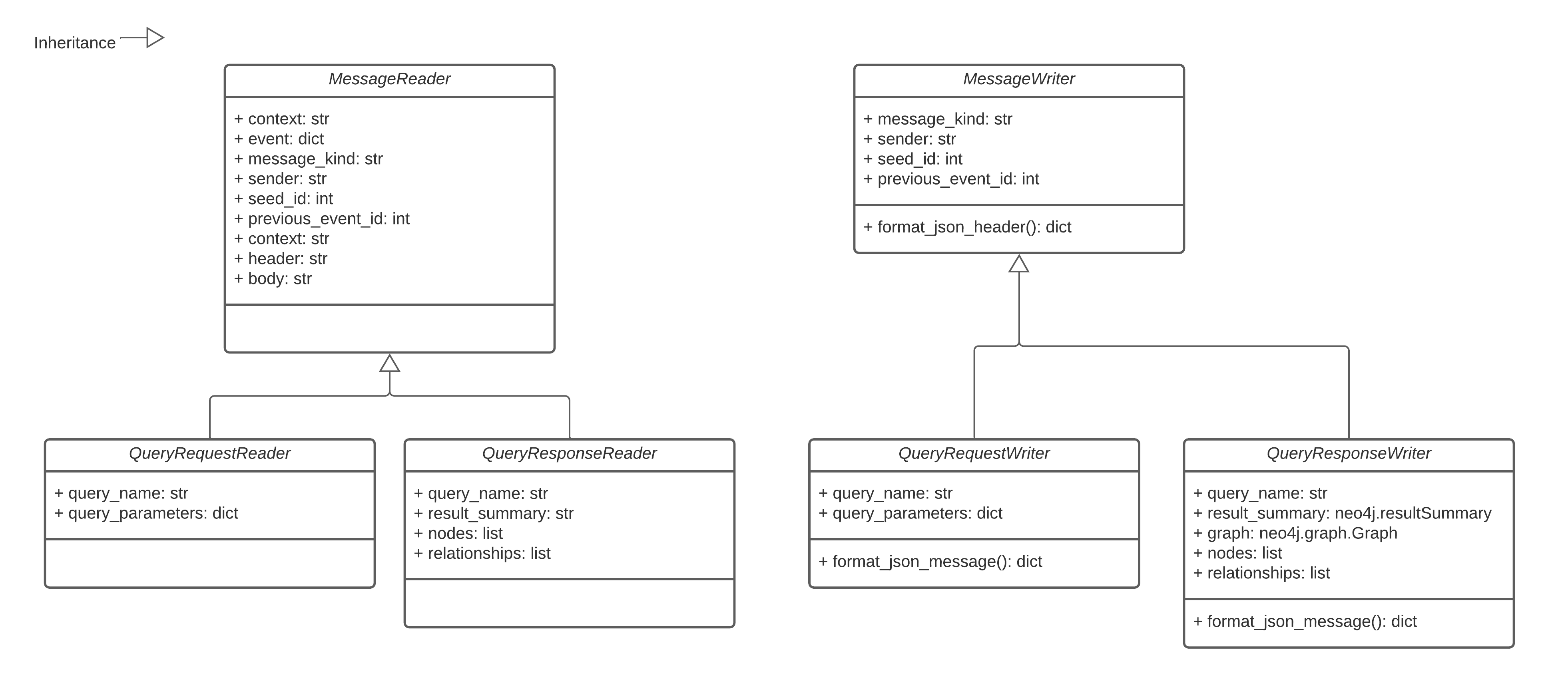
These query-based classes are enough to handle messages in the core Trellis functional loop of running database queries and interpreting results to see if they trigger any further queries.
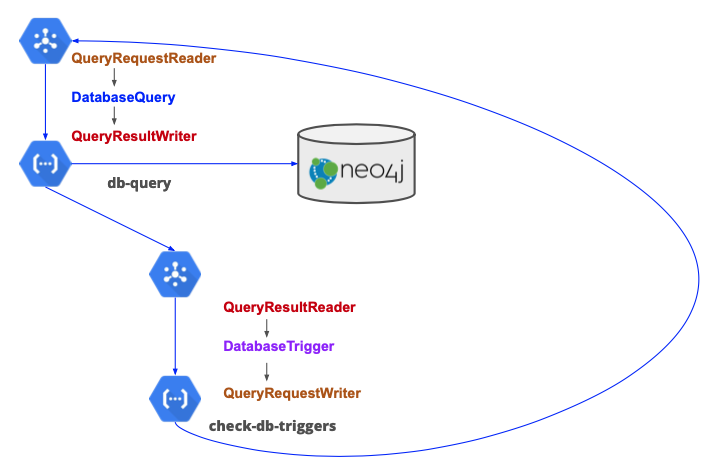
Switching to the Neo4j database driver¶
My primary reason for switching from py2neo to the official Neo4j driver was to support parameterized queries. Parameterized queries allow you to define queries using variables to represent property values and then supply the values at query runtime. This has several benefits:
It allows Neo4j to cache and reuse the same query plan for queries with the same structure but different property values.
And most importantly to me, it allows for aggregation of performance metrics using Halin.
It allows me to easily return node and relationship using the Graph class.
Aggregating query performance metrics¶
I had previously been forming queries using string concatenation in my Python application and then passing the queries to Neo4j. Even though lots of queries followed the same plan, Neo4j didn’t recognize them as the same because I hadn’t parameterized them. So, when I would open the Query Performance tab in Halin every query would be listed as a single entry.
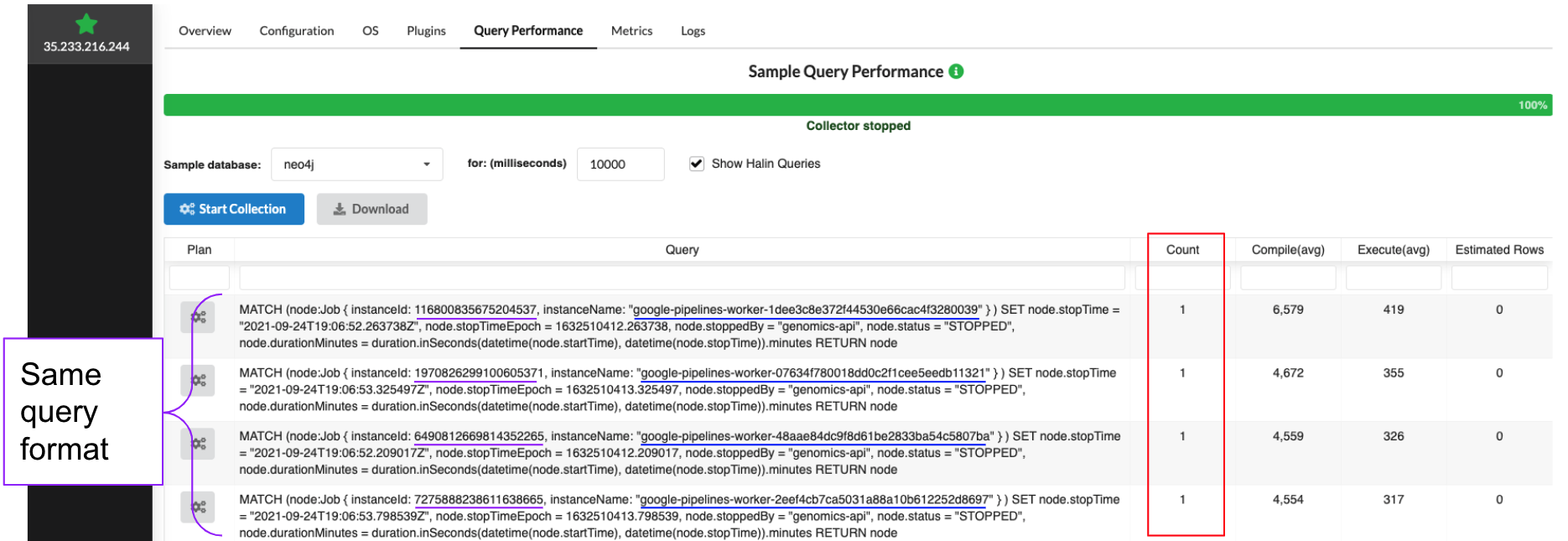
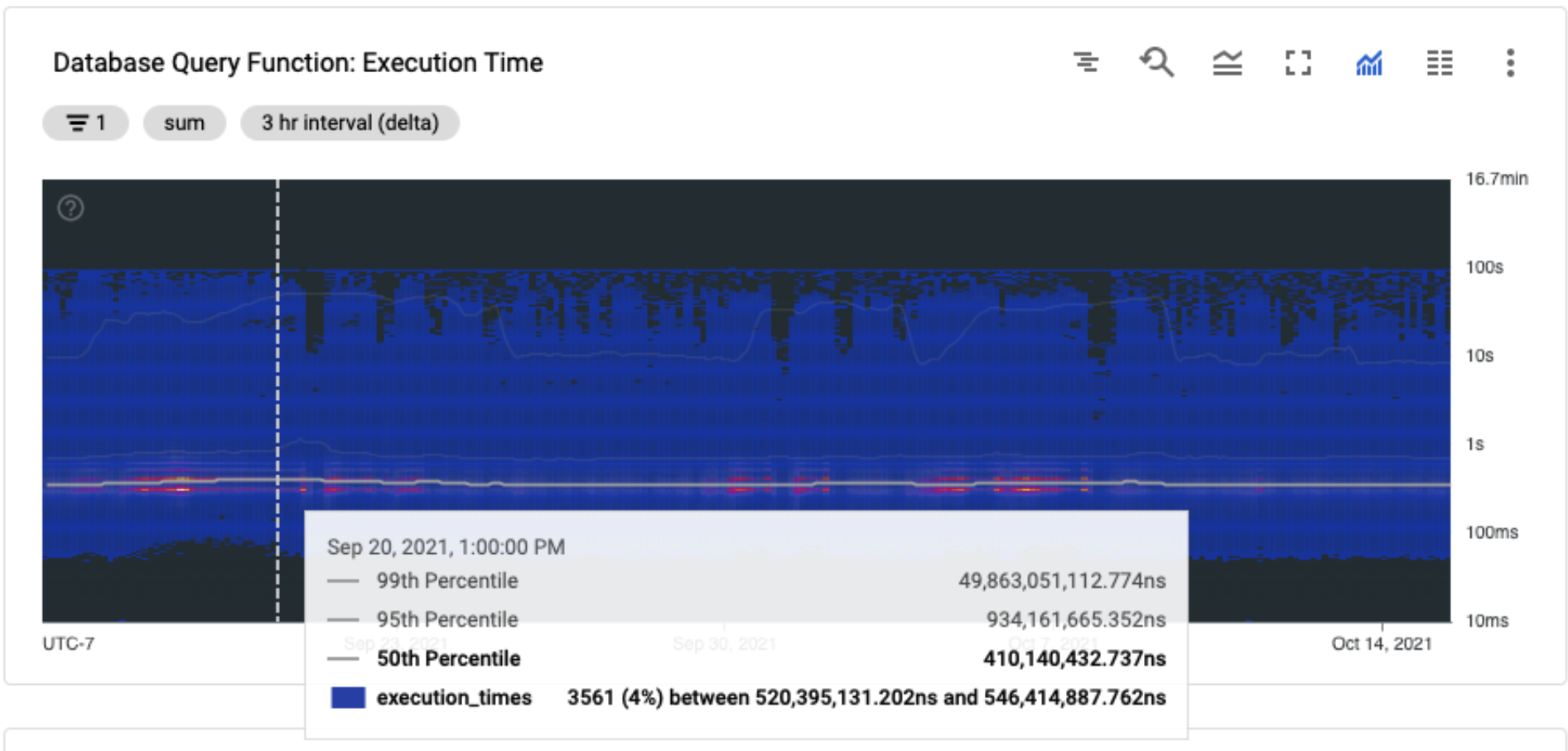
This was an issue because I noticed that my overall query performance had been slowly degrading as I had continued to update the database model and add more data, and I wasn’t sure why. This screenshot from my Cloud Monitoring dashboard shows a heatmap of execution times for the db-query Trellis function responsible for processing database queries. Here the average execution is about 410ms, up from 350ms a few months prior. You can also see that there are plenty of queries that take between 1 and 100 seconds (timeout), which is also an issue I want to address. But without being able to aggregate query performance metrics it’s hard to identify which queries are performing poorly.
Here you can see an example of where I converted a single query to use parameters and was able to aggregate execution metrics over 57 instances of the query. It also made it easier for me to read and interpret the query by replacing long property values with shorter and more informative variable names.

Returning node and relationship information¶
The Neo4j driver also makes it easy to return node and relationship results. Where previously I had only used node metadata to activate triggers, now I can create triggers to respond to nodes or relationships.
After running a Cypher query, the Trellis db-query function returns two types of objects, a Graph and a ResultSummary. The Graph class made it easy to design relationship queries because it includes attributes that allow you to view all of the nodes or relationships that have been returned.
with driver.session() as session:
if write_transaction:
graph, result_summary = session.write_transaction(_stored_procedure_transaction_function, query, **query_parameters)
else:
graph, result_summary = session.read_transaction(_stored_procedure_transaction_function, query, **query_parameters)
return graph, result_summary
Simplifying database triggers¶
When trying to write documentation for adding new features to Trellis, I realized how cumbersome and obtuse it was to create database triggers. One reason for this was that each trigger was coded as a unique Python class. During the rush to “minimum viable product” this was valuable because it afforded me a lot of flexibilty to implement solutions. In some cases, rather than implement a complex and time-consuming design solution I could just implement a quick workaround by adding hacky trigger logic. While this allowed me to get a (mostly) working product out it led to a lot of inconsistent and varied logic that is difficult to interpret.
So, with 1.3 I ditched the custom trigger classes for a standardized and simplified trigger logic. And with the new database driver I was able to expand triggers to respond to nodes as well as relationships.
My first step in simplifying triggers was to reduce the amount of metadata parameters that could be used to control trigger activation.
Old trigger parameters |
New trigger parameters |
|---|---|
node labels |
node labels |
message header labels |
relationship types |
node properties |
|
banned node labels |
|
node property instance types |
|
message body properties |
|
Trellis configuration properties |
In 1.3, there are two types of triggers: node and relationship. Node triggers respond to queries that return metadata for a single node. Relationship triggers can be activated by queries results that include (2) nodes connected by a single relationship. Node triggers are designed to activate when a new node is created or the state of the data object that correspond to changes (e.g. the storage class of the object changes). Relationship triggers are designed to be activated when the state of a workflow the node is involved in changes (e.g. a relationship was added to a “Ubam” node indicating it was generated by a “Fastq-to-Ubam” job). Most triggers will be activated by relationships because it is important to establish the context of a node within a workflow graph before deciding how to proceed with further processing.
Defining triggers using YAML¶
Another goal for simplifying triggers was to be able to define them using a simple text format. Requiring potential users to understand a programming language to interact with Trellis represents a significant barrier to entry and also limits the flexibility of Trellis customization. A value of using serverless functions is that each of them can be defined using a different language. I don’t recommend that, but if someone wanted to define their own database trigger function, I would want them to be able to design it to use the same triggers I use. Text formats like JSON or YAML afford that flexiblity.
I opted to define triggers using YAML primarily because PyYAML allows me to load Python objects directly from YAML documents. This made it straightforward to implement a DatabaseTrigger class and load triggers.
import yaml
class DatabaseTrigger(yaml.YAMLObject):
yaml_tag = u'!DatabaseTrigger'
def __init__(
self,
trigger_type,
start,
query,
end=None,
relationship=None):
self.trigger_type = trigger_type
self.start = start
self.query = query
self.end = end
self.relationship = relationship
fastq_to_ubam_trigger = """
--- !DatabaseTrigger
name: LaunchFastqToUbam
type: relationship
start:
label: PersonalisSequencing
end:
label: Fastq
properties:
sample: sample
readGroup: read_group
relationship:
type: GENERATED
query: launchFastqToUbam
"""
trigger = yaml.load(fastq_to_ubam_trigger, Loader=yaml.FullLoader)
Database trigger fields¶
Trigger field |
Description |
|---|---|
name |
Trigger name |
type |
Indicate whether the trigger is activated by a node or relationship |
start:label |
Define the kind of start node that can activate this trigger. |
start:properties |
Indicate the properties of the start node that should be passed to the query activated by this trigger. |
end:label |
Define the kind of end node that can activate this trigger. |
relationship:type |
|
Trellis configuration properties |
Supporting Node & Relationship Triggers¶
Using parameterized queries¶
Stored queries¶
Dynamically generating queries¶
Reducing index footprint¶
Create indexes on labels with a) low population and b) high connectivity then start queries from there and traverse outwards
Reducing the overall number of indexes
Reducing storage footprint of indexes